Dictionary Attacks on the Kryptonizer
In my previous blog entry, I discussed the Kryptonizer security gadget and made some calculations about its security level. Some of the questions remained unanswered and I've conducted a bit more research to find out what's going on. There's some more interesting findings. If you haven't read it, check out the previous entry for all the background.
Starting Prefix Revisited
If you remember from the previous blog post, the reason why there's a starting prefix is for character set variety:
I've been thinking about this a bit and especially checked out many images of Kryptonizers on the Internet and figured out what they mean by that. I do not want to get in hot water regarding copyright law, therefore I am careful and will not show the images here. I can link to them, however:
- https://www.kryptonizer.de/
- https://unicum-merchandising.com/sortiment/kryptonizer/
- https://www.elv.de/elv-kryptonizer-zur-sicheren-verschluesselung-von-passwoertern.html
- https://unishop-stuttgart.de/accessoires/80/kryptonizer
- https://www.itforlife.de/ihre-sicherheit-ist-uns-wichtig/
However, I've transcribed the content of each one to the extent that was possible (some are only partial). If you want to play around with the machine-readable data, here it is as JSON format. Here's the result. We give the content, then judge if all 12 characters are unique for the Kryptonizer, then analyze if there's an uppercase, lowercase, number or special character in the "Start" value:
| Start | Lookup | All unique? | UC in start? | LC in start? | Number in start? | Special in start? |
|---|---|---|---|---|---|---|
| ?3Ig | =4iGJ-nB | Yes | Yes | Yes | Yes | Yes |
| 8R?a | Ws3#HYcu | Yes | Yes | Yes | Yes | Yes |
| Q2#x | p3C!HzpC | No | Yes | Yes | Yes | Yes |
| ?K9a | =kZ1xfYg | Yes | Yes | Yes | Yes | Yes |
| =B7a | ?cR1-Szt | Yes | Yes | Yes | Yes | Yes |
| 9S-d | Xt5#eG | Yes | Yes | Yes | Yes | Yes |
| 2.Ly | #8Y | Yes | Yes | Yes | Yes | Yes |
| 8jKb | T5z#eG?4 | Yes | Yes | Yes | Yes | No |
| 1dI= | bD?5YsEA | Yes | Yes | Yes | Yes | Yes |
| 4uR? | x1F3Yi#9 | Yes | Yes | Yes | Yes | Yes |
| 5-Rc | =6rCuSgM | Yes | Yes | Yes | Yes | Yes |
| 7uG# | Ra4y!Jp6 | Yes | Yes | Yes | Yes | Yes |
| u5-L | 2t#F8b?Q | Yes | Yes | Yes | Yes | Yes |
It is pretty clear that the "start value, with one exception, always contains exactly one character of each set (uppercase, lowercase, number, special characters). The one example, I'm guessing, is either a pre-production unit or a photoshopped image. The reason is that it is exceptionally unlikely that randomly generated strings would hit four out of four character sets in 12 out of 13 cases. A proof on that is to follow, but first there's more calculations to be made. Bear with me.
Estimating the Start Character Set
So now we'll need to re-think what characters are actually used. From the examples above, we can gather that at least the following characters are included:
ABCDEFGHIJKLMQRSTWXYZ abcdefgijknprstuxyz 123456789 !#-.=?
This are, in total 55 characters, so we're missing another 11 if the assertion in the original Kryptonizer text is true. This also means, and I'm not sure how I missed this the first time, that it cannot be 26 + 26 + 10 + x, because we have too many special characters for this. Therefore, a reasonable assumption in my opinion is that certain characters out of the alphabets are omitted for the sake of clarity (e.g., O and 0 or l and I).
Here's my conjecture as to what the character set is that will give us 66 characters:
ABCDEFGHIJKLMNPQRSTUVWXYZ abcdefghijkmnopqrstuvwxyz 123456789 !#-.=?$
This gives us 25 + 25 + 9 + 7 = 66 characters in the character set. With that conjectured out of the way, we jump to the re-assessment of the security of the start prefix. Remember the security of the security if just the whole charset were selected randomly from would simply be:
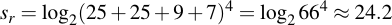
I.e., about 24.2 bits. But that's not what we have here, we have a forced choice from each character set. We need to take the product of the single characters sets and multiply them by the number of possible permutations. For four characters, the number how you can distribute those sets is 24, or 4!. Therefore, the amount of security is:
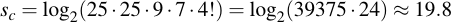
You'll see the security of the prefix, by forcing one character of each set yields a reduction in security by about 4.4 bits. In other words, a more than twenty fold decrease in security because of a constraint which I'm fairly certain was meant to improve security.
When looking at this for the first time, this seems paradox. After all, the attacker is forced to brute force using a larger character set, therefore it's more difficult for her, right? Unfortunately, wrong: Even when each of the four characters would be randomly chosen from the pool of all 66 characters, the attacker would have to use the largest character set, as she has no way of knowing which characters were chosen randomly. By forcing character sets, this gives additional knowledge to the attacker as to what characters can not be. For example, if in our brute force efforts we choose a capital "K" for the first letter, we now know we need not check for any other uppercase letters for the second, third and fourth position – a great decrease in security.
This is a fallacy that is ubiquitous everywhere when dealing with passwords. Many websites even require at least a certain number of special characters, numbers and combination of uppercase/lowercase characters. I've even seen special password rulesets that allow characters not in certain places, e.g., no uppercase letters as the first character or no special characters as the last. For good, randomly generated passphrases, this makes the generated passwords actually less secure because it puts constraints on the keyspace which an attacker can easily exploit.
The Alphabet is Irrelevant
The alphabet, i.e., the pool of characters that is chosen from, is only one parameter that matters where the other is length. The relationship between the two is fairly obvious because the size of the keyspace S is:
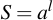
Where a is the size of the alphabet and l is the length of the randomly generated passphrase. For example, when using only lowercase letters, i.e., an alphabet size of 26 and a passphrase length of 8 characters, we get a keyspace size of:
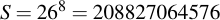
Expressing this in bits, we simply take the binary logarithm:
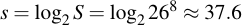
I.e, a keyspace of around 37 bits. But let's say we only want to use numbers, i.e., we reduce our alphabet size to 10. It can be easily seen that the same equivalent security level can be generated, but obviously a longer passphrase needs to be chosen. To determine the necessary length for a keyspace, you only have to take the logarithm to the base of your target alphabet size and round that value up. In our example:
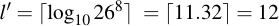
So even when we cut down our alphabet size to almost one third, we only need to supply four more characters – 12 instead of 8 – and have the same equivalent security level, as can be easily shown:
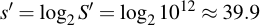
Back to Exceptional Unlikeliness
I would have been disappointed had you taken my word for the "exceptionally unlikely" claim that I've previously made without any doubt. Without any math. Let's quantify the exceptional unlikeliness of hitting one character out of each character set 12 times in a row. This is very easy to do for us now that we have the keyspaces for both completely random selection and the one for the chosen variant (both calculations in the previous section):
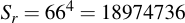
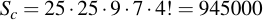
The latter one is a perfect subset of the former. What this means is that we can take Sr as the complete keyspace and estimate the ratio, i.e., the fraction of passwords that also fulfill the "chosen" criteria:
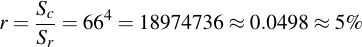
I.e., about one in twenty passwords fulfills the criteria that it contains exactly one of each of the original character sets (by the way, exactly the same as the reduction in security we calculated beforehand). This means the probability to chose twelve of these at random and always hit the 5% subset equals:
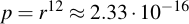
The probability to win the German lottery (6 out of 49) is 1 : 13983816. It is more likely to win the German lottery twice in a row that it is to choose twelve Kryptonizers at random and always hit those character sets.
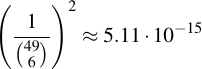
This supports the hypothesis that the character sets are deliberately chosen.
Uniqueness of Characters
When you look at the table, you'll also see a column that checks for uniqueness among all 12 (4 + 8) letters printed on the Kryptonizer. And, with the exception of one (where I'm going to argue again that it's probably a faulty image), they are completely unique. What would be the probability that 12 such images were entirely unique and no duplicate letters could be encountered? Let's even make it more difficult for us and argue that the start is fixed (and given according to the scheme we determined earlier). Let's assume the 8 remaining letters are truly randomly chosen.
The first letter of the lookup table has 62 options out of the original 66 if we don't want to choose one of the ones contained in the starting symbol. The probability of not hitting anything that was used before, therefore, is
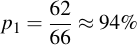
For the second one, we have one less option (because we now have chosen already one letter of the lookup table which we don't want to use anymore), therefore:
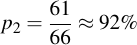
Now, we're interested in the probability of all these eight choices be made correctly, therefore we calculate the product of them all:
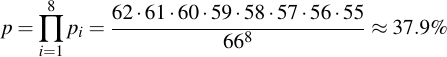
That doesn't seem like bad odds, almost 40%. But remember, this is for choosing a single Kryptonizer. We know of at least 12 of these which fulfill the criteria. The chance for all 12 to have this property even though they were maybe randomly chosen therefore is:
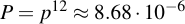
I.e., it's less than about 1 in 100000. I do not count myself that lucky and will assume from now on that all 12 letters are created so there are no duplicates.
Natural Language Constraints
In the last blog entry, I've not even covered the constraints of natural language and the possibility of duplication of passphrases due to the "loss of precision" when simply grouping letters together (i.e., in the lookup table A is the same as B is the same as C). I've thought about this some more and here's my findings:
I've started with a German dictionary and, from that file, taken all nouns without umlauts that are between 6 and 10 characters:
$ cat german.dic | grep -E '^[A-Z][a-z]{5,9}$' | wc -l
160430
Then, I've grouped them according to the Kryptonizer lookup, resulting in digits 0-7 for each character:
Aachen -> 000214 Aachener -> 00021415 Aachenerin -> 0002141524 Aachenern -> 000214154 [...] Zytologie -> 776434221 Zytoplasma -> 7764530540 Zytosol -> 7764543 Zytotoxin -> 776464724 Zytotoxine -> 7764647241 Zytotoxins -> 7764647245
Then, recalculating the reduction in options, this results in little improvement:
$ cat german.dic | grep -E '^[A-Z][a-z]{5,9}$' | ~/decryptonizer | sort | uniq | wc -l
156527
But, again, this calculation is wrong! I'll go into detail why this is.
Re-enumerating Word Groups
Imagine a simple form of a Kryptonizer and a simple source alphabet. Our source alphabet only contains four letters (ABCD) and after "Kryptonizing", only two groups 0 and 1 remain. The translated alphabet would have a total of 4 characters, this time for simplicity only lowercase: "abcd". Keep in mind the original Kryptonizer has a source alphabet of 26 letters (A to Z), eight groups and a translated alphabet size of roughly 66. But here's our simplified variant:
AB -> [abcd] CD -> [abcd]
Now image four source words that we will translate:
AAABBB CDCDCD DBACCB ACDBAD
Now, if we translate them according to the groups they fall into, we get five different values:
AAABBB 000000 CDCDCD 111111 DBACCB 100110 ACDBAD 011001
As you see, option one and two (AAABBB and CDCDCD) are exact inverses of each other and option three and four (DBACCB and ACDBAD) as well. I will show now that these collapse into the same values, and even if we had a number of more groups that also for the last two, that in a setup with eight lookups, values like 255225 or 733773 would also fall into the same class and can be merged together into one. The reason for this is because when we do brute forcing, we need to do exhaustive search of the lookup tables anyways and therefore any option that fulfills the constraints is tried as a permutation of its lookup table. The pattern "000000", for example, only means: All characters have the same value. The pattern "100110" means: Character at offset 0, 3 and 4 have the same value and the characters at offset 1, 2 and 5 have also the same value.
When we therefore look at how bruteforcing using a dictionary attack would be done, we would proceed by selecting an alphabet first and then trying the permutations. Let's do this now:
Imagine the correct lookup table of the Kryptonizer we're attacking would be this:
AB -> c CD -> b
The user would have chosen DBACCB as a passphrase and consequently have generated the passphrase baabba (we're completely ignoring the fixed prefix for now). In a brute force approach, we first collapse the dictionary into its equivalent classes of words. This can be easily done by re-enumerating translated words and assigning them ascending groups going from left-to-right. Therefore:
AAABBB 000000 -> 000000 CDCDCD 111111 -> 000000 DBACCB 100110 -> 011001 ACDBAD 011001 -> 011001
We can see only two words remain: 000000 and 011001. Now we go through each dictionary entry and exhaustively search the lookup tables and all permutation of used variables.
Searching word: 000000 Lookup table 0 = a 1 = -: 000000 -> aaaaaa Lookup table 0 = b 1 = -: 000000 -> bbbbbb Lookup table 0 = c 1 = -: 000000 -> cccccc Lookup table 0 = d 1 = -: 000000 -> dddddd Searching word: 011001 Lookup table 0 = a 1 = b: 011001 -> abbaab Lookup tacle 0 = a 1 = c: 011001 -> accaac Lookup tadle 0 = a 1 = d: 011001 -> addaad Lookup table 0 = b 1 = a: 011001 -> baabba <- MATCH
What you can see is the following: Not only do words collapse into their respective groups, but also brute forcing can be restricted to the subset of used groups within that word, i.e., usually this is never going to be the whole eight groups.
Back to Natural Language
Now we're back at our dictionary attack. We now not only translate into groups, but then re-enumerate each word as we described it in the chapter before:
Aachen -> 000214 -> 000123 Aachener -> 00021415 -> 00012324 Aachenerin -> 0002141524 -> 0001232413 Aachenern -> 000214154 -> 000123243 [...] Zytologie -> 776434221 -> 001232445 Zytoplasma -> 7764530540 -> 0012345325 Zytosol -> 7764543 -> 0012324 Zytotoxin -> 776464724 -> 001212032 Zytotoxine -> 7764647241 -> 0012120324 Zytotoxins -> 7764647245 -> 0012120324
Now let's see if we only output the unique collapsed groups, how much effort we have:
$ cat german.dic | grep -E '^[A-Z][a-z]{5,9}$' | ~/decryptonizer | sort | uniq | wc -l
58288
Wow, from more than 160000 words we can reduce the effort to only 58288! That is roughly a 3-fold increase in attack performance right off the bat. And for most of the words in the dictionary we need not even try to bruteforce all eight lookup table entries, but only a subset. In particular, here is the number of words that fall into each category, on the left side the number of used lookup table fields and on the right side their respecive occurrences:
1 1 2 69 3 1342 4 9429 5 22889 6 18478 7 5446 8 634
For bruteforcing n words which contain k different letters, not taking the starting prefix into account, the overall number of attempts therefore is:
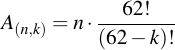
Again with the simple explanation that for the first letter we bruteforce, we need to have 62 tries (4 are already known that it can't be from the starting prefix!), for the second letter we then have 61 tries, and so on. Doing the math, here's what comes out – I've given some examples of words that fall into the respective groups:
| k | n | Ak | log2 Ak | Cumulative Ak | Cumulative log2 Ak | Example |
|---|---|---|---|---|---|---|
| 1 | 1 | 62 | 6.0 | 62 | 6.0 | Effeff |
| 2 | 69 | 260958 | 18.0 | 261020 | 18.0 | Erpresser, Feldklee, Pfeffer |
| 3 | 1342 | 304526640 | 28.2 | 304787660 | 28.2 | Erdsonden, Feldeffekt, Haschisch |
| 4 | 9429 | 126238092120 | 36.9 | 126542879780 | 36.9 | Abbaublock, Recherche, Staatsmann |
| 5 | 22889 | 17773771773360 | 44.0 | 17900314653140 | 44.0 | Abbauenzym, Adressbit, Leitstelle |
| 6 | 18478 | 817866836699040 | 49.5 | 835767151352180 | 49.6 | Fragerunde, Nebellicht, Zwergfalke |
| 7 | 5446 | 13498742092711680 | 53.6 | 14334509244063860 | 53.7 | Abbausohle, Jugendpark, Zinshandel |
| 8 | 634 | 86430616374009600 | 56.3 | 100765125618073460 | 56.5 | Blockzuges, Dialysator, Wortgewalt |
Let's assume the worst case, we need to brute force the whole dictionary. The sum of A values in the table above amount to 100765125618073460 different tries for all words in the dictionary. Remember, this is checking for all 160k words even though we're saving ourselves some work by only testing roughly one third of them (because some fall into equivalence classes). What this means is that the total complexity to perform a 160k-word dictionary attack against an completely unknown Kryptonizer is:
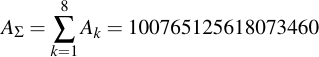
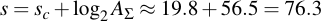
Note that the majority work occurs with just the last few words, words that take up all eight lookup table entries. If you only want to brute force the vast majority of dictionary words, i.e., that use groups 1-6, you end up with a total complexity of 69.4 bits. For groups 1-5 it's even only 63.8 bits. Both well within the realm of brute-forcability.
Conclusion
Dictionary attacks on the Kryptonizer are feasible even without knowing anything about the Kryptonizer's content. Due to the mentioned design flaws above (in particular, the uniqueness of characters in the selection on one hand and the grouping of letters) the brute force complexity is vastly reduced. Even worse, many of ads promoting the Kryptonizer pretend like you can use really simple words and you're still going to have a secure passphrase come out of it. That is not the case. Words like "Zugang" (the one mentioned in all the examples), "Passwort" or "letmein" are all 5-group words. All German month names are 4- or 5-group names with the exception of May (Mai = 3) and October (Oktober = 6).
The takeaway is: Weak input passwords will lead to weak output passwords, even when using the Kryptonizer. How secure passphrases should be chosen is well-known. If you do, you do not need to rely on a Kryptonizer. It might create the impression of good security, but is only as secure as the input you feed it.