Cryptanalysis of the Kryptonizer
I received an invitation for the it-sa trade show/expo, a fairly popular IT security venue with the tagline "Home of IT Security". Attached was little keychain gimmick they called the "Kryptonizer". This is how it looks:

Here's the translation:
INFO: Kryptonizer is your individual translator, which transforms each simple word in a cryptic password. Kryptonizer serves as a learning tool to playfully learn dealing with crypto-passwords. The method shown here can be arbitrarily transferred and can be randomly varied.
NOTES: The printed translation codes are generated from a character set of 66 characters. Because every Kryptonizer has its own unique translation-code, the same word (e.g., "Edward") is translated every time into a different crypto-code.
We recommend to use at least 8 character words. Reason: The larger the original character set, the more secure the cryptic passphrase is. The additional starting characters ensure the variety of characters. Please generate for additional security only one crypto-passphrase with this product and change it should you lose the keychain.
BACKGROUND: Password hackers routinely have it far too easy to access personal data on the Internet. The reason is obvious: Passphrases which we can remember are usually not very cryptic, but use common names or words such as "Snowden" or "Admin".
THIS IS HOW IT WORKS:
- Think of a word (the longer, the more secure)
- Encrypt every letter by itself
- Retrieve your Crypto-Passphrase
So the way it works is you carry the "Kryptonizer" on your keychain and construct your password the following way: You first take the fixed 4-character prefix, remember a simple word, and then simply substitute each letter of the word by the given 8-character lookup table. Also note that the original explanation contains an error, it says on one hand that the static prefix is "4uR=?" (five characters) but then only speaks of "4uR?" again, i.e., four characters. I had done my calculations originally with 5 fixed characters and only later noticed that discrepancy -- it should all be fixed now and hopefully in my analysis there's no inconsistencies. If so, please let me know.
In the example that is printed on the instructions, you have the following lookup table:
| Entry | Value |
|---|---|
| Prefix: | 4uR? |
| ABC: | x |
| DEF: | 1 |
| GHI: | F |
| JKL: | 3 |
| MNO: | Y |
| PQRS: | i |
| TUV: | # |
| WXYZ: | 9 |
"4uR?" + lookup("Z") + lookup("U") + lookup("G") + ... + lookup("G") =
= "4uR?" + "9" + "#"+ "F" + ... + "F" =
= "4uR?9#FxYF"
Now is it a good idea to use such a gadget? My gut feeling tells me it's not a good idea, but I'm actually quite curious. So let's do the math!
Attacker Model 1: Kryptonizer Content Secret
Our first attacker model is the strongest one, namely: The attacker only knows that I used the Kryptonizer to generate a password. They do not know anything about the content of my Kryptonizer. Also we assume that the content of each "Kryptonizer" was generated by a fair TRNG.
With that knowledge, for a "simple word" of length l, was is the total strength of the passphrase? It's actually quite interesting. An naive approach would be to calculate the keyspace S as
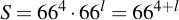
And therefore, the corresponding security level s in bits to be
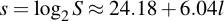
I.e., roughly 24 bits constant and 6 bits of security for each character. However, this calculation is completely wrong. The reason that it's wrong is that for passphrases that are greater than 8 characters, the attacker knows that the alphabet will repeat. However, we know not what 8 characters are in that alphabet. So how do we go about it? Well, let's first look at the number of permutations of alphabets there are, given by the binomial coefficients:
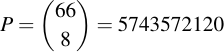
Note, as before, we're assuming that each lookup table value occurs exactly once. With that knowledge, we can simply enumerate all lookup tables and, in each one, choose one of 8 alphabet characters. Mathematically, this means:
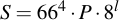
This means the overall equivalent security level in bits is
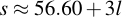
Which leads to a very interesting fact: For a passphrase, apologies, crypto-passphrase length that converges against infinity, the latter approach scales better. However, for small passwords, simple exhaustive enumeration might be the better approach even. Of course we want to find out at which point, and 6th grade math comes to the rescue:
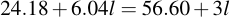
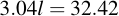
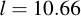
I.e., up to a password length of about 15 characters (i.e., l = 11), an attacker would use simple exhaustive search, then switch to the lookup table thing. In any case, 15 characters gives a password strength of about 90 bits, which is fairly decent, while the simple example password given on the Kryptonizer itself (l = 6) comes to 75 bits.
Attacker Model 2: Kryptonizer Content Known to Attacker
When the Kryptonizer content, which you're supposed to wear as a keychain, becomes public knowledge, the situation drastically changes suddenly. Now, the fixed prefix is known and the alphabet is as well. The whole security level degrades to:
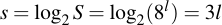
Which means even a 20-character passphrase will have merely 60 bits of equivalent security. I.e., it becomes instantly an entirely broken scheme.
Attacker Model 3: Kryptonizer Content Partially Known to Attacker
Now let's say you are using the Kryptonizer on multiple services on the Internet and one of them is really poorly implemented, and violates best practice by storing passphrases in clear text. It's not hard to imagine that people who blunder with security that much also, by mere accident, lose the database of their users. So how much of the lookup table can be inferred by knowing a password that was generated with that scheme?
It's not clear to know, because even the longest password does not guarantee that all lookup table entries are hit. Let's say the basic source passphrase is randomly generated. Then, mathematically, we're dealing with the Coupon Collector's Problem, where the eight lookup table entries correspond the different coupon types and every new letter of the password is a coupon draw. This is, by the way, a rather interesting mathematical problem and after knowing it I finally realize why I never managed to collect all collectible soccer stickers which I tried to chase after as a kid.
In any case, for different values of l and assuming the input passwords are entirely random, we can calculate the number of most likely discovered lookup table characters and the average number of discovered characters. It can be easily constructed by constructing the Markov Probability chain: you representing the probability state changes of the graph as a matrix and repeatedly multiply it with a probability vector (starting with the starting probability of 100% that nothing was discovered). In result, you'll get a vector after t multiplications (corresponding to t draws), which gives you the individual probabilities to discover n coupons after t draws. The average number of discovered characters of the lookup table can simply be calculated by summing the individual discovery probability with the number of discovered characters, or mathematically speaking, the average value A equals:
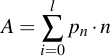
| Value of l | Highest likelihood to discover | Average number of discovered |
|---|---|---|
| 0 | 0 | 0.0 |
| 1 | 1 | 1.0 |
| 2 | 2 | 1.9 |
| 3 | 3 | 2.6 |
| 4 | 3 | 3.3 |
| 5 | 4 | 3.9 |
| 6 | 4 | 4.4 |
| 7 | 5 | 4.9 |
| 8 | 5 | 5.3 |
| ... | ... | ... |
| 24 | 8 | 7.7 |
| 25 | 8 | 7.7 |
I.e., already with l = 5, so five characters used from the lookup table, it is most likely that the attacker knows half the table.
Now let's say an attacker knows q of the 8 characters, where q ranges from 0 to 8. In this case, the attacker can take the lookup approach for most characters while successively brute forcing the others. Let's be more concrete: Say that a Kryptonizer-password is leaked and it is "Y!lQzaV9Vp". We immediately learn two things:
- The prefix is "Y!lQz", which is going to be identical to all other passphrases
- In the lookup table, we have at least a, V, 9 and p as potential characters. We know half of it.
Now let's say we're trying to brute force another 10-digit passphrase (i.e., l = 5) that was generated by Kryptonizer of the same user. In our first run, we assume we know all of the alphabet, hence:
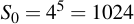
I.e., this is an incredibly fast check with only 10 possibilities. If this fails, we assume there is one character that is not from the alphabet and all the others are:
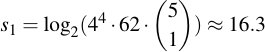
So we assume that we know 4 of the 5 characters, but for the last one we need to guess all remaining 62 possibilities. Additionally, we do not know where that additional character occurs, so we need to try out all 5 possible places. It still is very doable at 18.3 bits of computational complexity, that's going to be almost instantaneous. More generally, therefore, the formula to calculate S when there are u unknown characters present and we know that k characters are present in the alphabet:
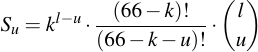
We can proceed to calculate the necessary computation power for all values of u up to the worst case where the new passphrase we're trying to guess consists exclusively out of letters which we do not have in our alphabet. Even then, knowing a few characters of the alphabet is beneficial for our attack since it gives us the letters which to exclude in the brute force search. The following table shows, for each possible value of u, the key space that needs to be searched both in terms of S as well as in equivalent security in bits, s. It additionally gives the cumulative s value, which, in this case, is so heavily dominated by each respective last u-run that all previous runs are almost negligible.
| u | Su | log2 Su | Cumulative log2 S |
|---|---|---|---|
| 0 | 1024 | 10.0 | 10.0 |
| 1 | 79360 | 16.3 | 16.3 |
| 2 | 2420480 | 21.2 | 21.3 |
| 3 | 36307200 | 25.1 | 25.2 |
| 4 | 267765600 | 28.0 | 28.2 |
| 5 | 776520240 | 29.5 | 30.0 |
I.e., with the leak of a single passphrase and only a few of the letters, all other passphrases generated with the same Kryptonizer are significantly weakened. The official advice is to only use the Kryptonizer once and generate a single passphrase with it, circumventing this issue. I still think that it's unlikely this is going to happen. Instead, my gut feeling (this is completely without empirical evidence, caveat emptor!) is that people are going to buy a Kryptonizer and input "AMAZON" for their amazon password, "EBAY" for their eBay password and so on and so forth.
Further Work
Note that if the Kryptonizer allowed for duplicate digits in the lookup table, the math changes a bit. Therefore one thing to validate is if this is possible – my gut feeling tells me it isn't – and possibly change the calculations around a bit. Also interesting would be if the characters which appear in the "Start" value cannot appear in the lookup table, which would also weaken the scheme further.
Finally, a linguistic approach to attack the Kryptonizer seems sensible here as well. Letter distributions in natural language have a large disparity from a uniform distribution, therefore the brute force approach could be chosen so that common letters (e.g., for English E, T, A, O, I, ...) have occurrence frequencies that correspond to their occurrence. Alternatively, we could calculate the complexity of a dictionary attack – this would be mainly a numerical effort, however, since it relies on actual dictionary data. It is my belief that this would further be a significant threat to the used scheme. And we've not even looked at the combination of letters in the mapping (e.g., the "DEF" lookup is going to appear extremely more often than "WXYZ", therefore making some lookup table entries almost meaningless).
And that's entirely ignoring the elephant in the room that someone else generates these passphrase lookup tables and prefixes. Someone who you'll have to trust. I'm not saying the manufacturer is inherently untrustworthy, all I'm saying is: any system that needs you to rely on a third party keeping something secret is less desirable than one where you generate the secret all by yourself.
I've actually done a few of the aforementioned expanded calculations and created a separate blog entry for those, if you're interested.
Conclusion
Generally, the problem is that weak input passphrases will lead to weak output passphrases. Creating passphrases that look "cryptic" might give the impression of hightened security, but if the underlying input is bad ("ZUGANG", "ADMIN", etc.) the resulting passphrases will also be bad.
Generally, when dealing with passwords, these are some key points that you should take care of:
- Use randomized passphrases
- Don't bother with "complex" alphabets, length is more important than special characters
- Use unique passphrases for each service
- Use a secure passphrase manager such as KeepassXC
- Don't put your passphrase on your keychain for everyone to see
My recommendation would therefore to not use a Kryptonizer and instead rely on proven methods of password storage, if possible. And if you do use it, keep it private (i.e., do not put it on your keychain).